Boost DeepSeek Models Using GeForce RTX 50 Series AI Computers
The newly launched DeepSeek-R1 model family is generating significant excitement within the AI community. It enables both enthusiasts and developers to run advanced reasoning models capable of problem-solving, performing math, and coding—all from the privacy of their local computers.
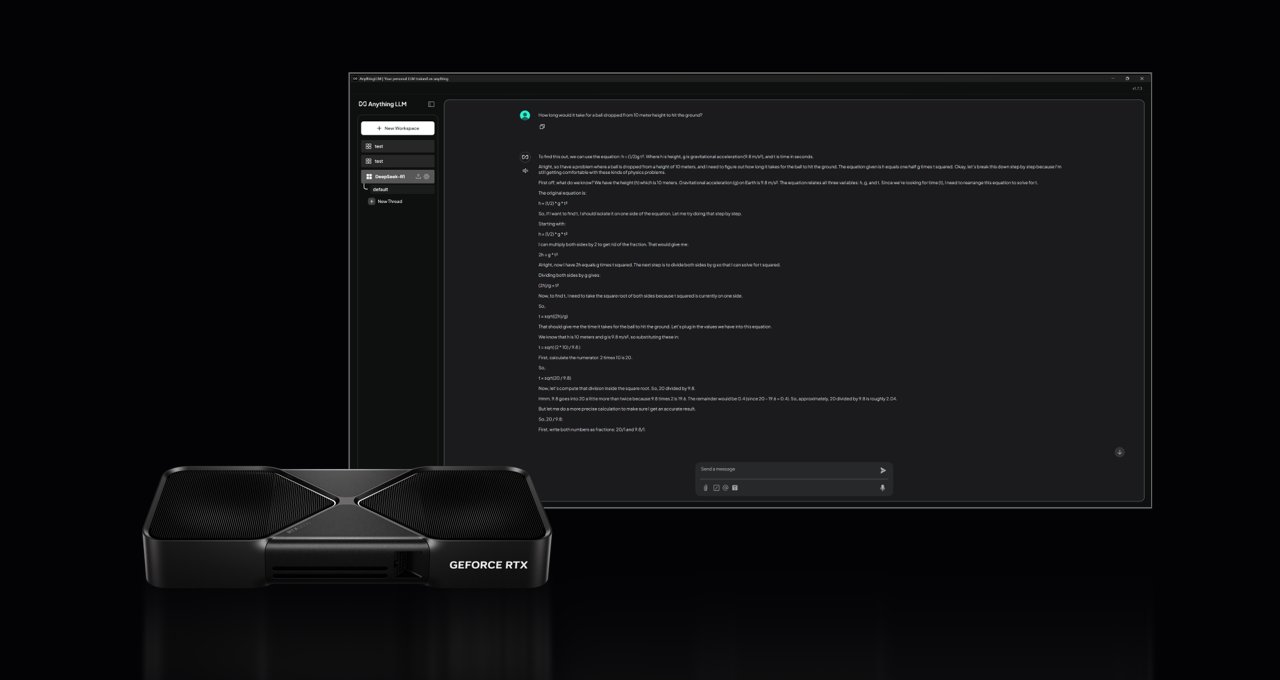
Equipped with an impressive power of up to 3,352 trillion operations per second, the NVIDIA GeForce RTX 50 Series GPUs can execute the DeepSeek models faster than other offerings currently available on the PC market.
Introduction to Reasoning Models
Reasoning models belong to a new category of large language models (LLMs) that prioritize “thinking” and “reflecting.” Unlike traditional models, these spend more time working through complicated problems while clearly narrating the steps to resolve a task.
The core idea is that all challenges can be tackled through deep thought and reasoning, similar to how humans approach problems. By dedicating more time, and thus more computational resources, to a problem, these LLMs can produce superior results. This strategy is referred to as test-time scaling, allowing the model to dynamically adjust its compute resources during inference to navigate complexities effectively.
These reasoning models significantly enhance user experiences on PCs. They can understand the user’s needs, take actions on their behalf, and even incorporate feedback about their reasoning process. This capability unlocks complex workflows, facilitating tasks like analyzing market research, solving intricate math problems, or debugging code.
What Distinguishes DeepSeek?
The DeepSeek-R1 family consists of models derived from a large 671-billion-parameter mixture-of-experts (MoE) framework. MoE models leverage several smaller expert models to tackle complex issues. The DeepSeek variety assigns subtasks to specific sets of experts, optimizing performance.
DeepSeek has utilized a technique known as distillation to develop a series of six smaller student models, varying from 1.5 to 70 billion parameters, based on the larger 671-billion-parameter model. The reasoning abilities of the large DeepSeek-R1 model have been transferred to these smaller Llama and Qwen student models, creating efficient local reasoning models that perform exceptionally well on RTX AI PCs.
Unmatched Performance on RTX
For reasoning models, inference speed is paramount. The GeForce RTX 50 Series GPUs feature dedicated fifth-generation Tensor Cores and are built upon NVIDIA’s Blackwell GPU architecture, which supports cutting-edge AI capabilities in data centers. The RTX line greatly accelerates DeepSeek’s performance, ensuring optimal inference speed on personal computers.
Utilizing DeepSeek on Popular Platforms
NVIDIA’s RTX AI platform provides a comprehensive selection of AI tools, software development kits, and models. This opens access to the DeepSeek-R1 capabilities on over 100 million NVIDIA RTX AI PCs globally, including those utilizing GeForce RTX 50 Series GPUs.
With powerful RTX GPUs, AI tools are readily accessible, even without an internet connection. This setup enhances privacy and reduces latency, as users do not need to upload sensitive information or queries to an online platform.
Explore the abilities of DeepSeek-R1 and RTX AI PCs through a wide range of available software, including Llama.cpp, Ollama, LM Studio, AnythingLLM, Jan.AI, GPT4All, and OpenWebUI, among others, for inference. Additionally, users can utilize Unsloth to fine-tune models with personalized data.