Evaluating ChatGPT and Microsoft Copilot’s Effectiveness in Responding to Obstetric Ultrasound Queries and Analyzing Reports
Evaluating AI Models in Obstetric Ultrasound Analysis
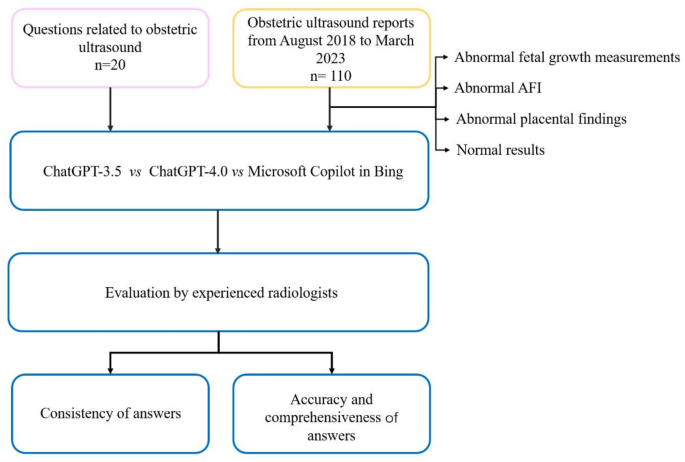
This article discusses a study that assessed the performance of various AI models—specifically ChatGPT-3.5, ChatGPT-4.0, and Microsoft Copilot—in answering questions and analyzing obstetric ultrasound reports. The goal was to examine their accuracy and reliability when it comes to critical medical scenarios.
AI Models Compared
Accuracy and Consistency
The study showed that ChatGPT-3.5 and ChatGPT-4.0 performed better than Copilot in answering a set of 20 ultrasound-related questions. Despite their performance difference, the statistical analysis revealed no major distinctions among the models, possibly due to the limited number of queries assessed. Nonetheless, in interpreting ultrasound reports, ChatGPT-3.5 and ChatGPT-4.0 were significantly more accurate than Copilot.
Statistical Performance
Correctness of Responses:
- ChatGPT-3.5: 83.86%
- ChatGPT-4.0: 84.13%
- Copilot: 77.51%
- Consistency of Responses:
- ChatGPT-3.5: 87.30%
- ChatGPT-4.0: 93.65%
- Copilot: 90.48%
While these models exhibited high accuracy in general report analysis, their performance in identifying abnormalities in fetal growth measurements was less impressive.
Interpreting Ultrasound Reports: Limitations and Issues
Challenges Faced by AI Models
The study identified several weaknesses in the AI models:
- Some responses were not entirely accurate or consistent. For instance, there were discrepancies in the descriptions of placental maturity among the tools. Both ChatGPT versions and Copilot occasionally offered contradictory interpretations.
- There were notable issues with fetal growth assessments, with observed accuracy rates being around 59-60% for both ChatGPT versions, while Copilot performed at only 50% accuracy.
Factors Contributing to Errors
A significant factor contributing to these inaccuracies is the training background of the AI models. They were trained on a broad mix of internet content rather than strictly scientific literature, potentially leading to errors in medical context. Variation in fetal growth standards based on ethnicity can also complicate consistent measurement understanding.
AI as Clinical Aids
Patient Interaction and Information Quality
While AI models can generate coherent and grammatically correct text, the lack of tailored interactions with users means they sometimes fail to clarify inquiries for better accuracy. This can lead to incomplete or misleading information being provided to users. Furthermore, potential security vulnerabilities in these systems raise concerns about their safe application in medicine. An incorrect interpretation made by an AI could critically affect medical decisions.
Emotional Impact of Misinterpretation
An example from the analysis highlighted a scenario where Copilot misdiagnosed a distance between the placenta and cervical os, incorrectly labeling it as "placenta previa." This type of error can create excessive emotional distress for pregnant women and their families.
Comparison of AI Models
In terms of general responses, each AI has unique strengths:
- ChatGPT-3.5: Known for concise and straightforward answers, often providing clear recommendations.
- ChatGPT-4.0: Offers detailed and comprehensive feedback, which includes summaries.
- Copilot: Utilizes a structured approach that thoroughly analyzes each section of an ultrasound report.
Study Limitations
The study has several limitations worth discussing:
- The small sample size, with only 20 questions and 110 reports, restricts how broadly the findings can be applied. Future research would benefit from larger and more varied samples.
- The study focused solely on textual data. Combining this data with multimodal approaches, such as images, could enhance the findings.
- Evaluations were made by ultrasound doctors of varying experience. Future studies should encompass input from maternal-fetal medicine specialists to refine the quality of evaluations.
In summary, while AI models like ChatGPT and Copilot hold promise for improving how medical professionals communicate complex ultrasound findings, their current limitations highlight the critical necessity for human oversight and additional rigor in validating their accuracy and applicability in clinical settings.