Guide to Using DeepSeek AI Locally on Any PC for Free
Protecting Your Data While Using DeepSeek R1
Are you concerned about your personal data being transmitted to countries like China when using large language models (LLMs) like DeepSeek R1? There is a way to address these privacy concerns: running these models locally on your own device.
Why Run LLMs Locally?
Running LLMs, such as DeepSeek R1 or Llama 3, on your machine can enhance privacy. By operating these models on your own hardware, you eliminate the risk of data being sent over the internet. Various tools exist to facilitate this, particularly for Windows, Mac, and Linux platforms.
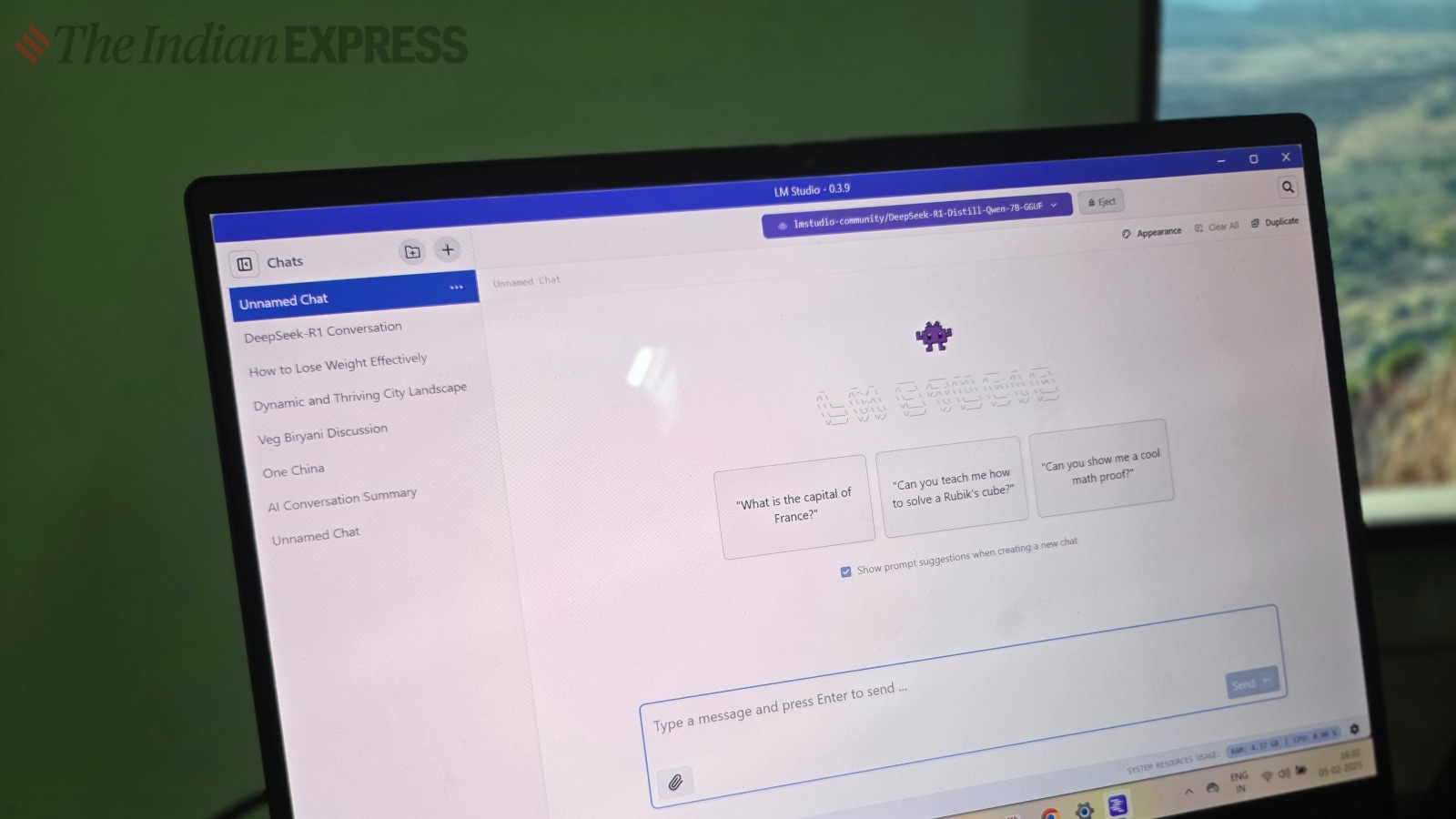
Recommended Tool: LM Studio
One of the standout tools we recommend is LM Studio, which is free to download and use from lmstudio.ai. This software supports various advanced models, including Llama 3.2, Mistral, Phi, Gemma, DeepSeek, and Qwen 2.5, allowing users to run them locally at no cost.
To achieve the best performance, it’s advisable to use a computer with a powerful CPU and GPU, and at least 16 GB of RAM. While smaller models can run on lower spec machines, complex models may require substantial resources.
Getting Started with DeepSeek
To run the DeepSeek model locally:
- Download LM Studio: Go to lmstudio.ai and download the application.
- Install DeepSeek: Follow the prompts to install the distilled version of DeepSeek R1, which contains approximately 7 billion parameters. This version is optimized for speed and efficiency.
Once installed, you may need to load the model initially, which can take anywhere from seconds to minutes, depending on the model size.
Important Considerations While Running AI Locally
Running an AI model on your PC requires attention to several important factors:
- Resource Monitoring: Keep an eye on your system’s RAM and CPU usage. If local resource usage is high, consider switching to an online model.
- Operating Modes: LM Studio offers three modes:
- User Mode: Basic features with minimal customization.
- Power User Mode: More advanced customization options.
- Developer Mode: Frees up additional customization features for extensive adjustments.
If you own a laptop with an NVIDIA GPU, you might notice improved performance.
Verifying Local Operation of the Model
To confirm that the model operates locally:
- Disconnect from Wi-Fi or Ethernet.
- Attempt to query the model. If you receive responses while offline, the model is indeed running on your device.
Performance Observations
When using a model like DeepSeek R1 on a laptop with an Intel Core Ultra 7 and 16 GB of RAM, response times can vary. In our testing, we found that while some responses were quick, others could take up to 30 seconds. The RAM usage averaged around 5 GB, with CPU utilization at approximately 35% during active use.
This variability does not necessarily undermine the model’s output quality but reflects the need for patience, particularly with more complex queries.
Privacy Benefits of Local Models
Using a local model offers significant advantages for those worried about data privacy. With no data transmission to external servers, users can benefit from cutting-edge AI technology without compromising their personal information. Unlike cloud services, where user data is often at risk, running LLMs locally offers peace of mind along with consistent results.
By adopting these methods, you can stay connected to the latest innovations in AI while ensuring your data remains private and secure.




