New Speech Models for Transcription and Voice Generation Unveiled by OpenAI
OpenAI’s New Speech Models: Enhancements and Features
OpenAI has rolled out advanced speech models aimed at enhancing speech-to-text and text-to-speech functionalities. These innovations focus on refining the accuracy of transcriptions and providing users with enhanced control over the generated voices. By improving automated speech applications, OpenAI aims to make these systems more versatile for various environments and scenarios.
Significant Improvements in Transcription
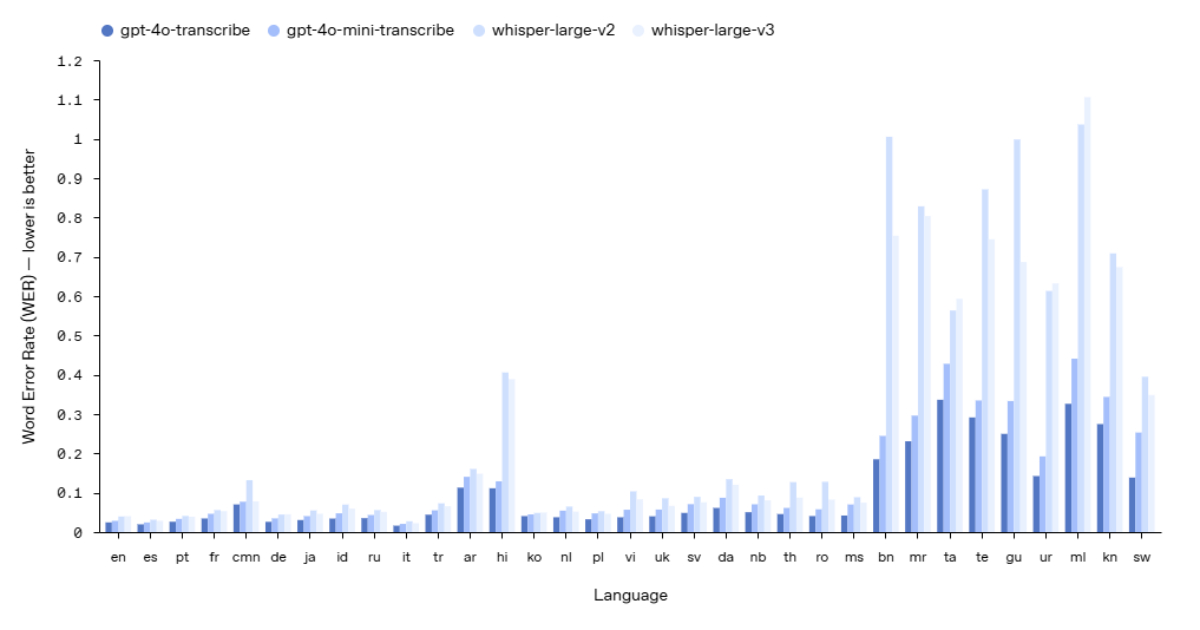
The introduction of the new gpt-4o-transcribe and gpt-4o-mini-transcribe models marks a considerable leap in transcription performance. These models exhibit a lower word error rate (WER) when compared to earlier versions, including Whisper v2 and v3. They’ve been optimized to better handle different accents, background noises, and varying speech paces, further enhancing their applicability in real-world situations such as customer service interactions, meeting note-taking, and multilingual dialogues.
Key Features of the New Models
Improved Accuracy: With enhanced training methods, including reinforcement learning and exposure to varied datasets, the new models show a marked reduction in transcription errors.
Better Speech Recognition: These models are trained to recognize spoken language more effectively, making them reliable for different use cases.
- API Availability: Users can access these advanced capabilities through the OpenAI speech-to-text API, integrating them easily into their applications.
Enhanced Text-to-Speech Capabilities
In addition to transcription improvements, the gpt-4o-mini-tts model introduces a level of flexibility that developers find highly beneficial. This model allows developers to specify the emotional tone and style of the AI’s speech. For instance, it can be tailored to sound empathetic, like a customer service representative, or more lively, resembling an engaging storyteller. This adaptability makes it easier to customize AI-generated speech for various applications, including automated assistance, narration, and other content creation tasks.
Noteworthy Aspects of Text-to-Speech Models
Steerability: Developers can instruct the AI on how to alter its speaking style based on the context or audience.
- Consistent Quality: OpenAI has prioritized voice quality to ensure that user needs for different applications are met effectively, despite the synthetic nature of the voices.
Community Feedback and Comparisons
The response to these new models has generally been positive. For example, industry professional Harald Wagener from BusinessCoDe GmbH praised the range of voices accessible within the OpenAI platform, emphasizing the effective support for tailoring responses to specific use cases.
Conversely, Luke McPhail highlighted in his commentary that while OpenAI’s models may not reach the heights of leading audio firms like ElevenLabs in terms of audio quality, the combination of OpenAI’s widespread market presence and user-friendly API could make it a favored choice for developers. Many users have noted that while OpenAI’s models might not yet outclass niche audio solutions, their ease of integration and functionality remains attractive for a wider range of applications.
Accessibility and Future Directions
OpenAI’s new speech-to-text and text-to-speech models are now available for developers to incorporate into their applications easily, notably through the Agents SDK. This tool helps streamline the process of integrating voice functionalities.
Looking ahead, OpenAI is committed to further enhancing both the intelligence and accuracy of its audio models. The company is also exploring avenues for developers to create custom voice solutions tailored to specific applications while ensuring compliance with safety and ethical guidelines. As these technologies evolve, they hold the potential to significantly impact various industries, enhancing communication and accessibility in digital environments.




